Ludwig


Declarative deep learning framework built for scale and efficiency.
![]()

![]()
IMPORTANT
 The Ludwig community has moved to Discord -- please join us there!¶
The Ludwig community has moved to Discord -- please join us there!¶
📖 What is Ludwig?¶
Ludwig is a low-code framework for building custom AI models like LLMs and other deep neural networks.
Key features:
- 🛠 Build custom models with ease: a declarative YAML configuration file is all you need to train a state-of-the-art LLM on your data. Support for multi-task and multi-modality learning. Comprehensive config validation detects invalid parameter combinations and prevents runtime failures.
- ⚡ Optimized for scale and efficiency: automatic batch size selection, distributed training (DDP, DeepSpeed), parameter efficient fine-tuning (PEFT), 4-bit quantization (QLoRA), and larger-than-memory datasets.
- 📐 Expert level control: retain full control of your models down to the activation functions. Support for hyperparameter optimization, explainability, and rich metric visualizations.
- 🧱 Modular and extensible: experiment with different model architectures, tasks, features, and modalities with just a few parameter changes in the config. Think building blocks for deep learning.
- 🚢 Engineered for production: prebuilt Docker containers, native support for running with Ray on Kubernetes, export models to Torchscript and Triton, upload to HuggingFace with one command.
Ludwig is hosted by the Linux Foundation AI & Data.
[!IMPORTANT] Our community has moved to Discord -- please join us!
💾 Installation¶
Install from PyPi. Be aware that Ludwig requires Python 3.8+.
pip install ludwig
Or install with all optional dependencies:
pip install ludwig[full]
🏃 Quick Start¶
For a full tutorial, check out the official getting started guide, or take a look at end-to-end Examples.
Large Language Model Fine-Tuning¶
![]()
Let's fine-tune a pretrained LLaMA-2-7b large language model to follow instructions like a chatbot ("instruction tuning").
Prerequisites¶
- HuggingFace API Token
- Access approval to Llama2-7b-hf
- GPU with at least 12 GiB of VRAM (in our tests, we used an Nvidia T4)
Running¶
We'll use the Stanford Alpaca dataset, which will be formatted as a table-like file that looks like this:
| instruction | input | output |
|---|---|---|
| Give three tips for staying healthy. | 1.Eat a balanced diet and make sure to include... | |
| Arrange the items given below in the order to ... | cake, me, eating | I eating cake. |
| Write an introductory paragraph about a famous... | Michelle Obama | Michelle Obama is an inspirational woman who r... |
| ... | ... | ... |
Create a YAML config file named model.yaml with the following:
model_type: llm
base_model: meta-llama/Llama-2-7b-hf
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
And now let's train the model:
ludwig train --config model.yaml --dataset "ludwig://alpaca"
Supervised ML¶
Let's build a neural network that predicts whether a given movie critic's review on Rotten Tomatoes was positive or negative.
Our dataset will be a CSV file that looks like this:
| movie_title | content_rating | genres | runtime | top_critic | review_content | recommended |
|---|---|---|---|---|---|---|
| Deliver Us from Evil | R | Action & Adventure, Horror | 117.0 | TRUE | Director Scott Derrickson and his co-writer, Paul Harris Boardman, deliver a routine procedural with unremarkable frights. | 0 |
| Barbara | PG-13 | Art House & International, Drama | 105.0 | FALSE | Somehow, in this stirring narrative, Barbara manages to keep hold of her principles, and her humanity and courage, and battles to save a dissident teenage girl whose life the Communists are trying to destroy. | 1 |
| Horrible Bosses | R | Comedy | 98.0 | FALSE | These bosses cannot justify either murder or lasting comic memories, fatally compromising a farce that could have been great but ends up merely mediocre. | 0 |
| ... | ... | ... | ... | ... | ... | ... |
Download a sample of the dataset from here.
wget https://ludwig.ai/latest/data/rotten_tomatoes.csv
Next create a YAML config file named model.yaml with the following:
input_features:
- name: genres
type: set
preprocessing:
tokenizer: comma
- name: content_rating
type: category
- name: top_critic
type: binary
- name: runtime
type: number
- name: review_content
type: text
encoder:
type: embed
output_features:
- name: recommended
type: binary
That's it! Now let's train the model:
ludwig train --config model.yaml --dataset rotten_tomatoes.csv
Happy modeling
Try applying Ludwig to your data. Reach out if you have any questions.
❓ Why you should use Ludwig¶
- Minimal machine learning boilerplate
Ludwig takes care of the engineering complexity of machine learning out of
the box, enabling research scientists to focus on building models at the
highest level of abstraction. Data preprocessing, hyperparameter
optimization, device management, and distributed training for
torch.nn.Module models come completely free.
- Easily build your benchmarks
Creating a state-of-the-art baseline and comparing it with a new model is a simple config change.
- Easily apply new architectures to multiple problems and datasets
Apply new models across the extensive set of tasks and datasets that Ludwig supports. Ludwig includes a full benchmarking toolkit accessible to any user, for running experiments with multiple models across multiple datasets with just a simple configuration.
- Highly configurable data preprocessing, modeling, and metrics
Any and all aspects of the model architecture, training loop, hyperparameter search, and backend infrastructure can be modified as additional fields in the declarative configuration to customize the pipeline to meet your requirements. For details on what can be configured, check out Ludwig Configuration docs.
- Multi-modal, multi-task learning out-of-the-box
Mix and match tabular data, text, images, and even audio into complex model configurations without writing code.
- Rich model exporting and tracking
Automatically track all trials and metrics with tools like Tensorboard, Comet ML, Weights & Biases, MLFlow, and Aim Stack.
- Automatically scale training to multi-GPU, multi-node clusters
Go from training on your local machine to the cloud without code changes.
- Low-code interface for state-of-the-art models, including pre-trained Huggingface Transformers
Ludwig also natively integrates with pre-trained models, such as the ones available in Huggingface Transformers. Users can choose from a vast collection of state-of-the-art pre-trained PyTorch models to use without needing to write any code at all. For example, training a BERT-based sentiment analysis model with Ludwig is as simple as:
ludwig train --dataset sst5 --config_str "{input_features: [{name: sentence, type: text, encoder: bert}], output_features: [{name: label, type: category}]}"
- Low-code interface for AutoML
Ludwig AutoML allows users to obtain trained models by providing just a dataset, the target column, and a time budget.
auto_train_results = ludwig.automl.auto_train(dataset=my_dataset_df, target=target_column_name, time_limit_s=7200)
- Easy productionisation
Ludwig makes it easy to serve deep learning models, including on GPUs. Launch a REST API for your trained Ludwig model.
ludwig serve --model_path=/path/to/model
Ludwig supports exporting models to efficient Torchscript bundles.
ludwig export_torchscript -–model_path=/path/to/model
📚 Tutorials¶
🔬 Example Use Cases¶
- Named Entity Recognition Tagging
- Natural Language Understanding
- Machine Translation
- Chit-Chat Dialogue Modeling through seq2seq
- Sentiment Analysis
- One-shot Learning with Siamese Networks
- Visual Question Answering
- Spoken Digit Speech Recognition
- Speaker Verification
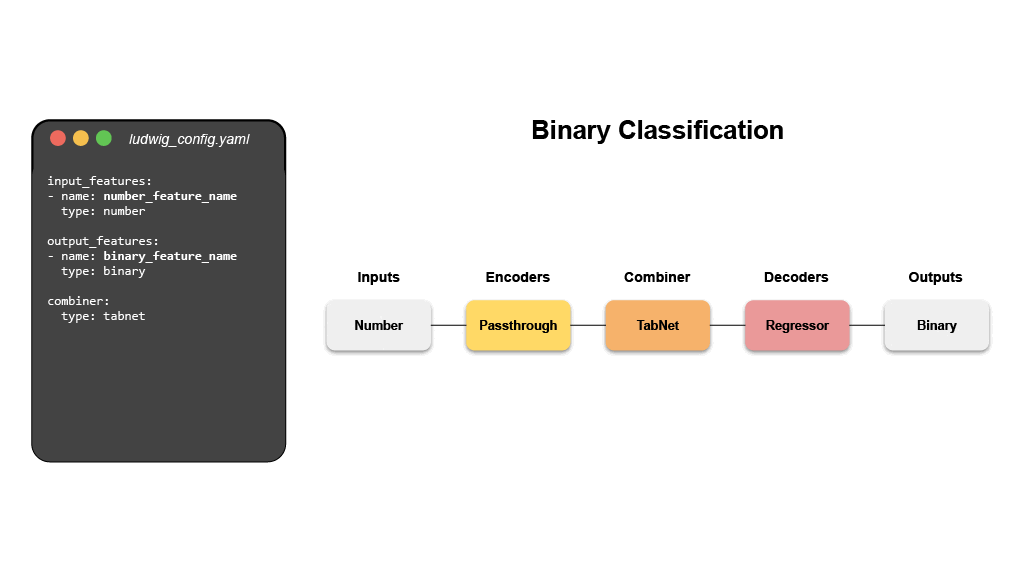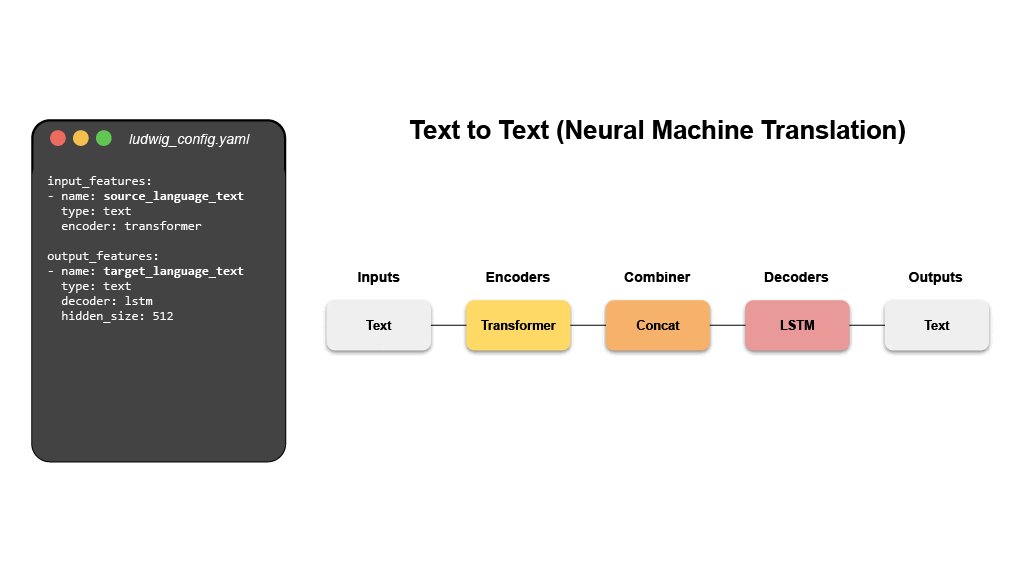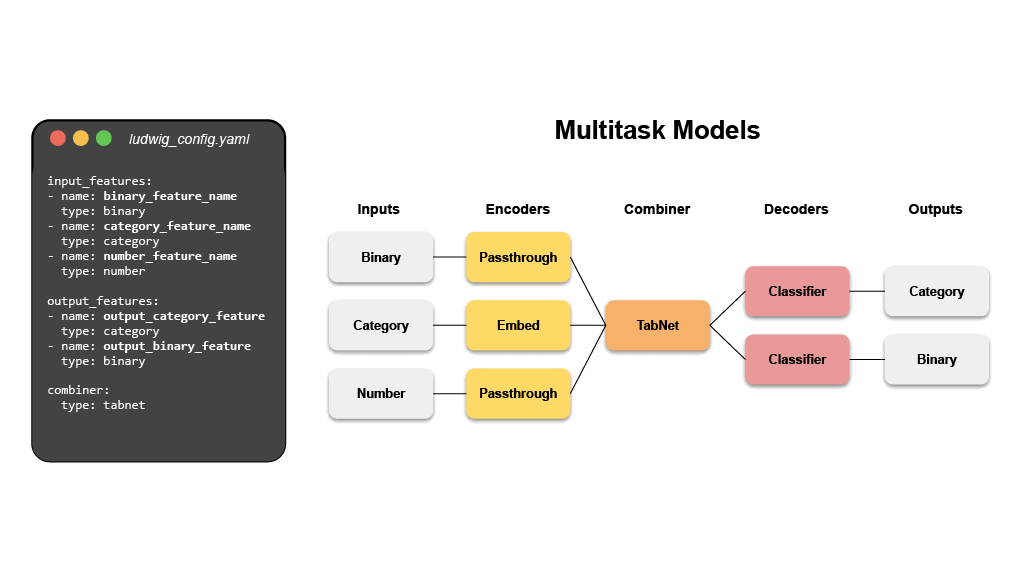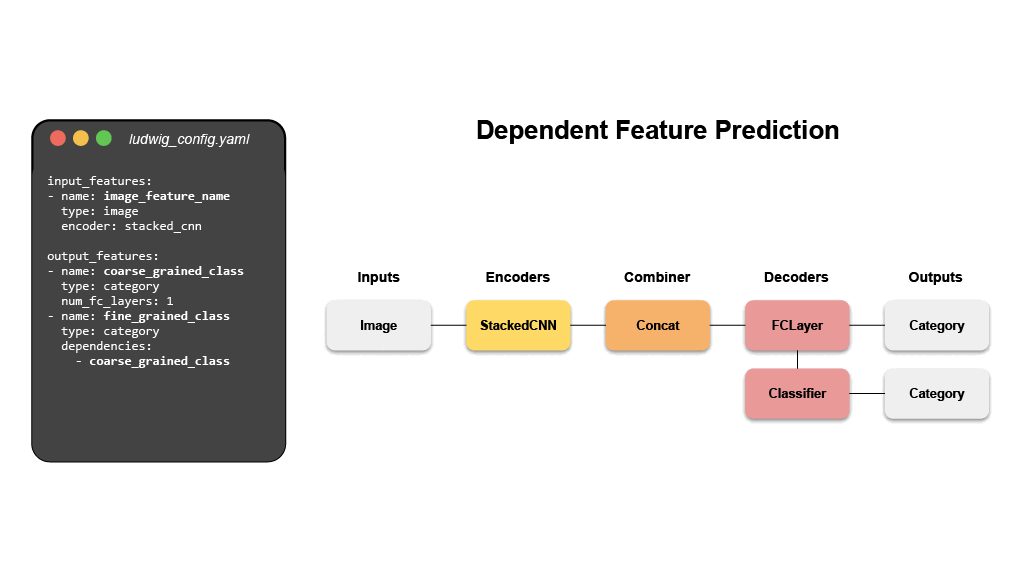
- Binary Classification (Titanic)
- Timeseries forecasting
- Timeseries forecasting (Weather)
- Movie rating prediction
- Multi-label classification
- Multi-Task Learning
- Simple Regression: Fuel Efficiency Prediction
- Fraud Detection
💡 More Information¶
Read our publications on Ludwig, declarative ML, and Ludwig’s SoTA benchmarks.
Learn more about how Ludwig works, how to get started, and work through more examples.
If you are interested in contributing, have questions, comments, or thoughts to share, or if you just want to be in the know, please consider joining our Community Discord and follow us on X!
🤝 Join the community to build Ludwig with us¶
Ludwig is an actively managed open-source project that relies on contributions from folks just like you. Consider joining the active group of Ludwig contributors to make Ludwig an even more accessible and feature rich framework for everyone to use!